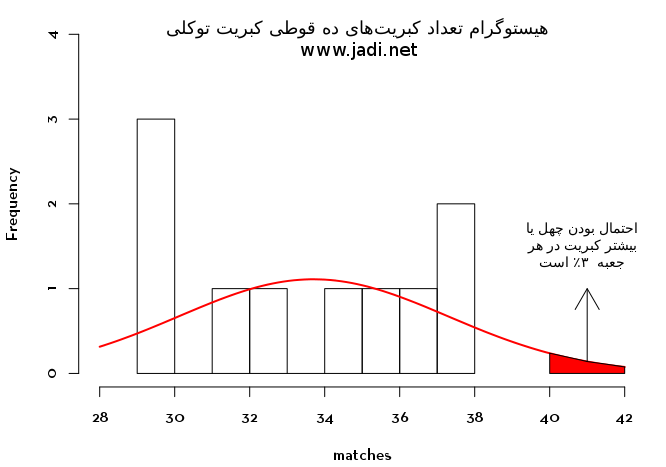
برای من اینطرف کشیدن ساعت معنی اش اینه که دیگه نمی تونم لای پرده رو باز بذارم و به موقع با نور آفتاب بیدار بشم. الان نور افتاب منو ساعت شش بیدار خواهد کرد. اصولا این ساعت رو اینطرف و اونطرف کشیدن چه تاثیری توی نور روز داره و در سطحی بالاتر، من که این روزها از هفت از خونه بیرون می رم در بهترین حالت شش و ربع می رسم، چقدر از سال تو تاریکی می یام بیرون و تو تاریکی بر می گردم. بذارین به پیروی از این مقاله که کار مشابهی کرده با بسته نرم افزاری جادویی R، با اعداد ور بریم.
مشخصه که نیاز به کتابخونه ای داریم که فانکشن های sunrise و غیره رو دارن پس:
> library(maptools)
و کافیه لت و لانگ تهران رو بهش بدیم:
> portsmouth <- matrix(c(51.4231, 35.6961), nrow=1)
و تاریخ:
> for_date <- as.POSIXct("2014-09-25", tz="Asia/Tehran")
و ازش بخوایم ساعت طلوع خورشید امروز رو بده:
> sunriset(portsmouth, for_date, direction="sunrise", POSIXct.out=TRUE)
day_frac time
newlon 0.2460366 2014-09-25 05:54:17
بله ظاهرا درسته ! خورشید ما رو ساعت ۵ و ۵۴ دقیقه صبح بیدار می کنه که مثل گرگ پاشیم بریم سر کار. این کتابخونه همچنین می تونه به ما زمان غروب، طول روز و ظهر رو هم بده و از اون باحالتر می تونه ورودی هایی به فرم بردارهایی از روزها قبول کنه. پس این تابع:
# adapted from http://r.789695.n4.nabble.com/maptools-sunrise-sunset-function-td874148.html
ephemeris <- function(lat, lon, date, span=1, tz="UTC") {
# convert to the format we need
lon.lat <- matrix(c(lon, lat), nrow=1)
# make our sequence - using noon gets us around daylight saving time issues
day <- as.POSIXct(date, tz=tz)
sequence <- seq(from=day, length.out=span , by="days")
# get our data
sunrise <- sunriset(lon.lat, sequence, direction="sunrise", POSIXct.out=TRUE)
sunset <- sunriset(lon.lat, sequence, direction="sunset", POSIXct.out=TRUE)
solar_noon <- solarnoon(lon.lat, sequence, POSIXct.out=TRUE)
# build a data frame from the vectors
data.frame(date=as.Date(sunrise$time),
sunrise=as.numeric(format(sunrise$time, "%H%M")),
solarnoon=as.numeric(format(solar_noon$time, "%H%M")),
sunset=as.numeric(format(sunset$time, "%H%M")),
day_length=as.numeric(sunset$time-sunrise$time))
}
می تونه لت و لانگ (طول و عرض) یک مکان رو بگیره و به اندازه date روز بعد از تاریخی که بهش گفتیم، به ما بگه که وضعیت نور روز چطوریه (اونم توی تایم زون مورد نظر):
> ephemeris(35.6961, 51.4231, "2014-09-25", 10, tz="Asia/Tehran")
date sunrise solarnoon sunset day_length
1 2014-09-25 554 1156 1757 12.05001
2 2014-09-26 555 1155 1755 12.01276
3 2014-09-27 555 1155 1754 11.97550
4 2014-09-28 556 1155 1752 11.93826
5 2014-09-29 557 1154 1751 11.90104
6 2014-09-30 558 1154 1750 11.86384
7 2014-10-01 558 1154 1748 11.82666
8 2014-10-02 559 1153 1747 11.78952
9 2014-10-03 600 1153 1745 11.75241
10 2014-10-04 601 1153 1744 11.71535
جالبه ولی نه به اندازه کافی. مغز اکثر ما نمودارها رو بهتر از جدول ها می فهمه. پس ما با توابع ggplot دو تا نمودار می کشیم. یکی نمودار نواری که نشون بده چه بخشی از روز نور آفتاب داره و چه بخش هایی تاریکه و یک نمودار دیگه که به سادگی بگه هر روز از سال چند ساعت نور داره.
library(ggplot2)
library(scales)
library(gridExtra)
# create two formatter functions for the x-axis display
# for graph #1 y-axis
time_format <- function(hrmn) substr(sprintf("%04d", hrmn),1,2)
# for graph #2 y-axis
pad5 <- function(num) sprintf("%2d", num)
daylight <- function(lat, lon, place, start_date, span=2, tz="UTC",
show_solar_noon=TRUE, show_now=TRUE, plot=TRUE) {
stopifnot(span>=2) # really doesn't make much sense to plot 1 value
srss <- ephemeris(lat, lon, start_date, span, tz)
x_label = ""
gg <- ggplot(srss, aes(x=date))
gg <- gg + geom_ribbon(aes(ymin=sunrise, ymax=sunset), fill="#ffeda0")
if (show_solar_noon) gg <- gg + geom_line(aes(y=solarnoon), color="#fd8d3c")
if (show_now) {
gg <- gg + geom_vline(xintercept=as.numeric(as.Date(Sys.time())), color="#800026", linetype="longdash", size=0.25)
x_label = sprintf("زمان در لحظه ترسیم نمودار: %s", format(Sys.time(), "%Y-%m-%d / %H:%M"))
}
gg <- gg + geom_hline(yintercept=as.numeric("0700"), color="#1000F6", linetype="longdash", size=0.25)
gg <- gg + geom_hline(yintercept=as.numeric("1815"), color="#1000F6", linetype="longdash", size=0.25)
gg <- gg + scale_x_date(expand=c(0,0), labels=date_format("%b "))
gg <- gg + scale_y_continuous(labels=time_format, limits=c(0,2400), breaks=seq(0, 2400, 200), expand=c(0,0))
gg <- gg + labs(x=x_label, y="",
title=sprintf("طلوع و غروب خورشید در %s\n%s ", place, paste0(range(srss$date), sep=" ", collapse="تا ")))
gg <- gg + theme_bw()
gg <- gg + theme(panel.background=element_rect(fill="#525252"))
gg <- gg + theme(panel.grid=element_blank())
gg1 <- ggplot(srss, aes(x=date, y=day_length))
gg1 <- gg1 + geom_area(fill="#ffeda0")
gg1 <- gg1 + geom_line(color="#525252")
if (show_now) gg1 <- gg1 + geom_vline(xintercept=as.numeric(as.Date(Sys.time())), color="#800026", linetype="longdash", size=0.25)
gg1 <- gg1 + scale_x_date(expand=c(0,0), labels=date_format("%b "))
gg1 <- gg1 + scale_y_continuous(labels=pad5, limits=c(0,24), expand=c(0,0))
gg1 <- gg1 + labs(x="", y="", title="طول روز به ساعت")
gg1 <- gg1 + theme_bw()
if (plot) grid.arrange(gg, gg1, nrow=2)
arrangeGrob(gg, gg1, nrow=2)
}
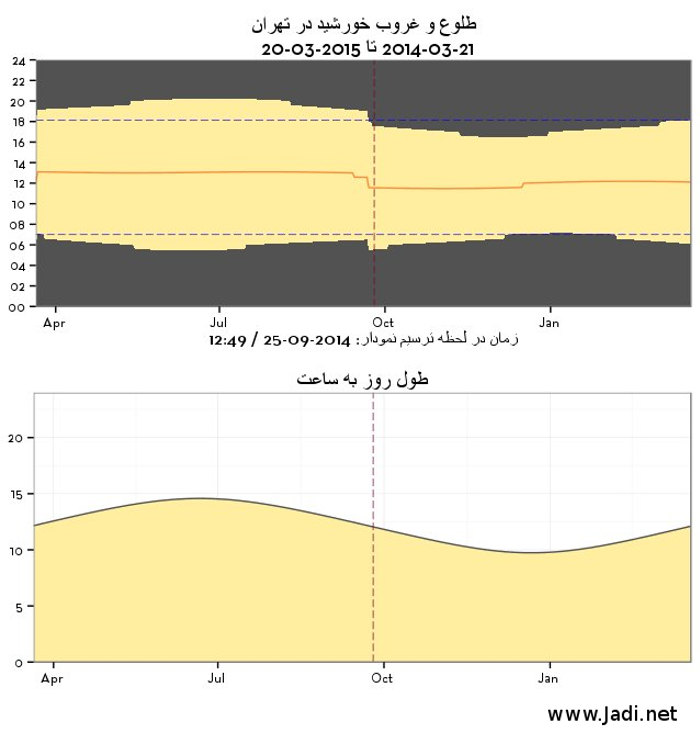
و حالا می تونیم هر چیزی بخوایم بکشیم.. مثلا برای تهران:
daylight(35.6961, 51.4231, "Tehran", "2014-03-21", 365, tz="Asia/Tehran")
باعث می شه به این برسیم:
![daylight_tehran]()
نمودار بالا نشون می ده چه ساعت های از روز صبح است و چه ساعت هایی شب و نمودار پایینی نشون دهنده ساعت های روشنایی است که در هر روز داریم و توش به راحتی می تونین تاثیر اینطرف اونطرف کشیدن ساعت رو ببینین.
خط عمودی در نمودار بالا مشخص کرده الان کجای سال هستیم و دو خط نقطه چین افقی می گن اگر یک نفر لازم باشه از هفت صبح از خونه بره بیرون و شش و ربع برگرده، چه زمانهایی از نور آفتاب در زندگی اجتماعی دور است. این نمودار ممکنه باعث بشه شما از کارتون استعفا بدین.
می بنین اعداد چقدر قشنگن؟




















 بنا به نتایجی که اخیرا سایت اوکلا که شغلش سنجیدن سرعت اینترنت است
بنا به نتایجی که اخیرا سایت اوکلا که شغلش سنجیدن سرعت اینترنت است